
在语言形态学和信息检索里,词干提取是去除词缀得到词根的过程─—得到单词最一般的写法。对于一个词的形态词根,词干并不需要完全相同;相关的词映射到同一个词干一般能得到满意的结果,即使该词干不是词的有效根。从1968年开始在计算机科学领域出现了词干提取的相应算法。很多搜索引擎在处理词汇时,对同义词采用相同的词干作为查询拓展,该过程叫做归并。
一个面向英语的词干提取器,例如,要识别字符串“cats”、“catlike”和“catty”是基于词根“cat”;“stemmer”、“stemming”和“stemmed”是基于词根“stem”。一根词干提取算法可以简化词 “fishing”、“fished”、“fish”和“fisher” 为同一个词根“fish”。
技术方案的选择
Python和R是数据分析的两种主要语言;相对于R,Python更适合有大量编程背景的数据分析初学者,尤其是已经掌握Python语言的程序员。所以我们选择了Python和NLTK库(Natual Language Tookit)作为文本处理的基础框架。此外,我们还需要一个数据展示工具;对于一个数据分析师来说,数据库的冗繁安装、连接、建表等操作实在是不适合进行快速的数据分析,所以我们使用Pandas作为结构化数据和分析工具。
环境搭建
我们使用的是Mac OS X,已预装Python 2.7.
安装NLTK
sudo pip install nltk
安装Pandas
sudo pip install pandas
对于数据分析来说,最重要的是分析结果,iPython notebook是必备的一款利器,它的作用在于可以保存代码的执行结果,例如数据表格,下一次打开时无需重新运行即可查看。
安装iPython notebook
sudo pip install ipython
创建一个工作目录,在工作目录下启动iPython notebook,服务器会开启http://127.0.0.1:8080页面,并将创建的代码文档保存在工作目录之下。
mkdir Codes cd Codes ipython notebook
文本处理
数据表创建
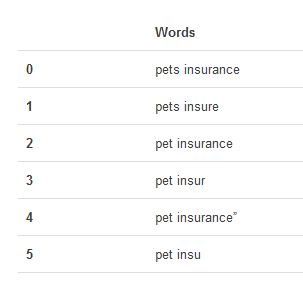
使用Pandas创建数据表 我们使用得到的样本数据,建立DataFrame——Pandas中一个支持行、列的2D数据结构。
from pandas import DataFrame import pandas as pd d = ['pets insurance','pets insure','pet insurance','pet insur','pet insurance"','pet insu'] df = DataFrame(d) df.columns = ['Words'] df
显示结果
NLTK分词器介绍
RegexpTokenizer:正则表达式分词器,使用正则表达式对文本进行处理,就不多作介绍。
PorterStemmer:波特词干算法分词器,原理可看这里:http://snowball.tartarus.org/algorithms/english/stemmer.html
第一步,我们创建一个去除标点符号等特殊字符的正则表达式分词器:
import nltk tokenizer = nltk.RegexpTokenizer(r'w+')
接下来,对准备好的数据表进行处理,添加词干将要写入的列,以及统计列,预设默认值为1:
df["Stemming Words"] = "" df["Count"] = 1
读取数据表中的Words列,使用波特词干提取器取得词干:
j = 0 while (j <= 5): for word in tokenizer.tokenize(df["Words"][j]): df["Stemming Words"][j] = df["Stemming Words"][j] + " " + nltk.PorterStemmer().stem_word(word) j += 1 df
Good!到这一步,我们已经基本上实现了文本处理,结果显示如下:

分组统计
在Pandas中进行分组统计,将统计表格保存到一个新的DataFrame结构uniqueWords中:
uniqueWords = df.groupby(['Stemming Words'], as_index = False).sum().sort(['Count']) uniqueWords

注意到了吗?依然还有一个pet insu未能成功处理。
拼写检查
对于用户拼写错误的词语,我们首先想到的是拼写检查,针对Python我们可以使用enchant:
sudo pip install enchant
使用enchant进行拼写错误检查,得到推荐词:
import enchant
from nltk.metrics import edit_distance
class SpellingReplacer(object):
def __init__(self, dict_name='en', max_dist=2):
self.spell_dict = enchant.Dict(dict_name)
self.max_dist = 2
def replace(self, word):
if self.spell_dict.check(word):
return word
suggestions = self.spell_dict.suggest(word)
if suggestions and edit_distance(word, suggestions[0]) <=
self.max_dist:
return suggestions[0]
else:
return word
from replacers import SpellingReplacer
replacer = SpellingReplacer()
replacer.replace('insu')
'insu'
但是,结果依然不是我们预期的“insur”。能不能换种思路呢?
算法特殊性
用户输入非常重要的特殊性来自于行业和使用场景。采取通用的英语大词典来进行拼写检查,无疑是行不通的,并且某些词语恰恰是拼写正确,但本来却应该是另一个词。但是,我们如何把这些背景信息和数据分析关联起来呢?
经过一番思考,我认为最重要的参考库恰恰就在已有的数据分析结果中,我们回来看看:

已有的5个“pet insur”,其实就已经给我们提供了一份数据参考,我们已经可以对这份数据进行聚类,进一步除噪。
相似度计算
对已有的结果进行相似度计算,将满足最小偏差的数据归类到相似集中:
import Levenshtein minDistance = 0.8 distance = -1 lastWord = "" j = 0 while (j < 1): lastWord = uniqueWords["Stemming Words"][j] distance = Levenshtein.ratio(uniqueWords["Stemming Words"][j], uniqueWords["Stemming Words"][j + 1]) if (distance > minDistance): uniqueWords["Stemming Words"][j] = uniqueWords["Stemming Words"][j + 1] j += 1 uniqueWords
查看结果,已经匹配成功!
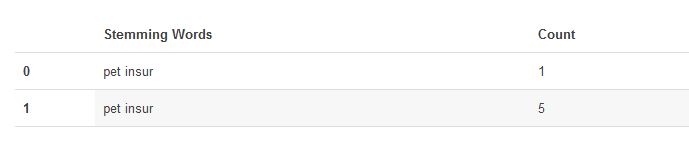
最后一步,重新对数据结果进行分组统计:
uniqueWords = uniqueWords.groupby(['Stemming Words'], as_index = False).sum() uniqueWords
到此,我们已经完成了初步的文本处理。

声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。TEL:177 7030 7066 E-MAIL:11247931@qq.com
Copyright © 2019-2024 51dongshi.com 版权所有
违法及侵权请联系:TEL:177 7030 7066 E-MAIL:11247931@qq.com 本站由北京市万商天勤律师事务所王兴未律师提供法律服务


