
我敢肯定,现在你已经知道我在O'Reilly Media上发布了有关Flask的一本书和一些视频资料。在这些上面,Flask框架介绍的覆盖面是相当完整的,出于某种原因,也有一小部分的功能没有太多的提到,因此我认为在这里写一篇介绍它们的文章是一个好主意。
这篇文章是专门介绍流媒体的,这个有趣的功能让Flask应用拥有这样一种能力,以分割成小数据块的方式,高效地为大型请求提供数据,这可能要花费较长的时间。为了说明这个主题,我将告诉你如何构建一个实时视频流媒体服务器!
什么是流媒体?
流媒体是一种技术,其中,服务器以数据块的形式响应请求。我能想到一个原因来解释为什么这个技术可能是有用的:
非常大的响应 。对于非常大的响应而言,内存中收集的响应只返回给客户端,这是很低效的。另一种方法是将响应写入磁盘,然后使用flask.send_file()返回文件,但是这增加了I/O的组合。假设数据可以分块生成,以小块数据的方式给请求提供响应是一种更好的解决方案。
实时数据 。对于一些应用,需要请求返回的数据来自实时数据源。在这个方面一个非常好的例子就是提供一个实时视频或音频。很多安全摄像机使用这种技术将视频数据流传输给Web浏览器。
使用Flask实现流式传输
Flask通过使用生成器函数对流式响应提供本机支持。生成器是一个特别的函数,它可以中断和恢复。考虑一下下面的函数:
def gen(): yield 1 yield 2 yield 3
这是一个运行三步的函数,其中每步返回一个值。描述生成器如何实现超出了本文的范围,但如果你有点好奇,下面的shell会话将给你说明生成器是如何被使用的:
>>> x = gen() >>> x>>> x.next() 1 >>> x.next() 2 >>> x.next() 3 >>> x.next() Traceback (most recent call last): File " ", line 1, in StopIteration
在这个简单的例子中你能看到,一个生成器函数可以顺序得返回多个结果。Flask使用生成器 函数这一特性来实现流式传输。
下面的例子说明了如何使用流式传输能够产生大的数据表,而不必将整个表放入内存中:
from flask import Response, render_template
from app.models import Stock
def generate_stock_table():
yield render_template('stock_header.html')
for stock in Stock.query.all():
yield render_template('stock_row.html', stock=stock)
yield render_template('stock_footer.html')
@app.route('/stock-table')
def stock_table():
return Response(generate_stock_table())
在这个例子中,你能看到Flask和生成器函数是如何一起工作的。返回流式响应的路由(route)需要返回一个由生成器函数初始化的Response对象。Flask然后采取调用生成器,并以分块的方式吧结果发送给客户端。
对于这个特殊的例子,如果你假设Stock.query.all()返回的数据库查询结果是一个迭代器,那么你能一次生成一个潜在大表的一行,因此无论查询中的字符数量有多少,Python过程中的内存消耗不会因为较大的响应字符串而越来越大。
多部分响应
上文提到了表的例子以小块的形式生成一个传统网页,各个的部分连接成最后的结果。对于如何生成较大的响应这是一个很好的例子,但更令人激动的事情是处理实时数据。
使用流式传输的一个有趣的应用是使用每个块来替换原来页面中的地方,这能使流在浏览器窗口中形成动画。利用这种技术,你可以让流中每个数据块成为一个图像,这给你提供了一个运行在浏览器中的很酷的视频输入信号!
实现就地更新的秘密是使用多部分响应。多部分响应由一个报头(header)和很多部分(parts)组成。报头包括多部分中的一种内容类型,后面的部分由边界标记分隔,每个部分中含有自身部分中的特定内容类型。
对于不同的需求,这里有一些多部分内容类型。对于具有流式传输的,每个部分替换先前部分必须使用multipart/x-mixed-replace内容类型。为了帮助你了解它到底是什么样子的,这里有一个多部分视频流传输的响应结构:
HTTP/1.1 200 OK Content-Type: multipart/x-mixed-replace; boundary=frame --frame Content-Type: image/jpeg--frame Content-Type: image/jpeg ...
正如你上面看到的,这个结构非常简单。主要的Content-Type头被设为multipart/x-mixed-replace,同时边界标记也被定义。然后每个部分中包括,有两个短横线的前缀,及这行上的边界字符串。每个部分有自己的Content-Type头,并且每个部分可以可选地包括一个说明所在部分有效载荷的字节长度的Content-Length头,但至少对图像浏览器而言,能够处理没有长度的流。
建立一个实时视频流媒体服务器
这篇文章中已经有足够的理论,现在是时候来建立一个将实时视频流式传输到Web浏览器的完整应用。
这里有很多方法将视频流式传输到浏览器,并且每个方法都有其优点和缺点。与Flask流特征协同工作的一个好方法是流式传输独立的JPEG图片序列。这就是动态JPEG。这被用于许多IP监控摄像机。这种方法具有较短的延迟时间,但传输质量并不是最好的,因为对于动态影像而言,JPEG压缩不是非常有效。
下面你可以看到一个非常简单但完整的Web应用。它可以提供一个动态JPEG流传输:
#!/usr/bin/env python
from flask import Flask, render_template, Response
from camera import Camera
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
def gen(camera):
while True:
frame = camera.get_frame()
yield (b'--framern'
b'Content-Type: image/jpegrnrn' + frame + b'rn')
@app.route('/video_feed')
def video_feed():
return Response(gen(Camera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)
这个应用导入一个Camera类来负责提供帧序列。在这个例子中,将camera控制部分放入一个单独的模块是一个很好的主意。这样,Web应用会保持干净、简单和通用。
该应用有两个路由(route)。/路由为主页服务,被定义在index.html模板中。下面你能看到这个模板文件中的内容:
Video Streaming Demonstration Video Streaming Demonstration
 }})
这是一个简单的HTML页面,只含有一个标题和图像标签。注意这个图像标签的src属性指向这个应用的第二个路由,这就是魔法发生的地方。
/video_feed路由返回流式响应。因为这个流返回要被展示在web页面上的图像,在图像标签的src属性中,URL指向这个路由。因为大多数/所有浏览器支持多部分响应(如果你找到一个不支持这个的浏览器,请告诉我),浏览器会通过显示JPEG图像流自动保持图像元素的更新。
在/video_feed路由中使用的生成器函数叫gen(),将Camera类的一个实例作为其参数。mimetype参数设置如上所示,并具有multipart/x-mixed-replace的内容类型和设为"frame"的边界字符串。
gen()函数进入一个循环,其中连续的从camera返回帧作为响应块。如上所示,这个函数通过调用camera.get_frame()方法要求camera提供帧,然后生成帧,使用image/jpeg内容类型将该帧格式化为响应块。
从摄像机获取帧
现在,所有剩下的就是实现Camera类,这必须连接摄像机硬件并从中下载实时视频帧。将这个应用硬件相关部分封装在一个类中的好处是,对于不同的人这个类可以有不同的实现,而应用的其他部分保持不变。你可以把这个类当做一个设备驱动,不管实际使用中的硬件设备而提供一个统一的实现。
从应用的其余部分分离出Camera类的另一个优点是,当实际上没有摄像机时,很容易能骗过应用程序,让它认为这里有摄像机,因为camera类能被实现为模拟摄像机而无需真实硬件。事实上,当我运行这个应用时,最简单的方式是测试流能做那些,而不需担心硬件,直到我已经使其他部分都正确运行。下面,你可以看到我使用的简单模拟摄像机实现:
from time import time class Camera(object): def __init__(self): self.frames = [open(f + '.jpg', 'rb').read() for f in ['1', '2', '3']] def get_frame(self): return self.frames[int(time()) % 3]
这个实现从磁盘中读取三个图像1.jpg、2.jpg、3.jpg,然后以每秒一帧的速率重复的依次返回。get_frame()函数使用当前时间,以秒来确定在给定的时刻返回哪三个帧。很简单吧?
要运行这个模拟摄像机,我需要创建三个帧。我使用gimp做了下面的图像:

因为摄像机是模拟的,你能在任何环境在运行这个应用!我将这个应用的所有文件放在了GitHub。如果你熟悉git,你可以使用下面的命令克隆它:
$ git clone https://github.com/miguelgrinberg/flask-video-streaming.git
如果你喜欢下载它,你可以在这里得到一个zip文件。
你安装好这个应用后,创建一个虚拟环境并在里面安装Flask。然后你就可以使用下面的命令运行这个应用:
$ python app.py
当你在你的Web浏览器中输入http://localhost:5000启动这个应用时,你会看到模拟视频流一遍遍地播放图像1、2、3。很酷吧?
有一次,应用中的所有都在运行,我启动了树莓派及其摄像机模块,并实现了一个新的Camera类来将树莓派变成一个视频流媒体服务器,使用picamera包来控制硬件。我不会在这里讨论这个camera类的实现,但你可以在源代码中的camera_pi.py文件中找到。
如果你有一个树莓派和一个摄像机模块,你可以编辑app.py文件从这个模块中导入Camera类,然后你就可以利用树莓派实时传输视频流,就像我在下面的截图中所做的:
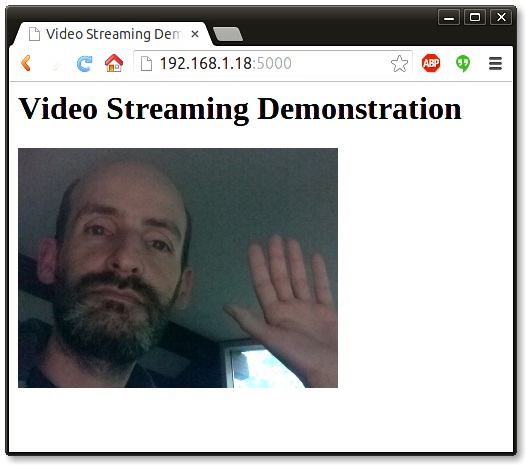
如果你想要让这个流传输应用适用于不同的摄像机,那么你要做的就是实现不同的Camera类。如果你最终能写一个并提供给我的Github上的项目,我将不胜感激。
流的限制
当Flask应用服务器提供常规请求时,请求周期短。工作线程(web worker)接收请求,调用处理函数并最终返回响应。一旦响应被发送回客户端,工作线程是空闲的,并准备执行下一个请求。
当接收到一个使用流式传输的请求时,工作线程在整个流式传输的持续时间内绑定在一个客户端上。当处理时间长而无止境的流时,比如来自摄像机的视频流,工作线程将锁定在一个客户端直到该客户端连接断开。这实际上意味着,除非采取特殊手段,否则应用程序能服务的客户端数量和工作线程是一样的。当使用Flask应用的debug模式时,这意味着只有一个工作线程,因此你将无法同时连接两个浏览器窗口来同时查看来自两个不同地方的数据流。
这里有办法克服这一重要的限制。在我看来,最好的解决方案是使用基于协程的Web服务器,如gevent,Flask完全支持它。通过使用协程gevent能够在一个工作线程上处理多个客户端,因为gevent修改Python I/O函数来进行必要的上下文切换。
结论
如果你错过了上面的内容,这篇文章中所包含的代码放在了这个GitHub库中:https://github.com/miguelgrinberg/flask-video-streaming。在这里,你可以找到一个通用的视频流传输实现而不需要一个摄像机,并且还有一个树莓派摄像头模块实现。
我希望这篇文章阐述了一些有关流技术的话题。我关注于视频流传输,因为这是一个我已有一些经验的领域,但除了流媒体视频之外,流传输技术还有很多其他的用途。例如,这种技术可以用来保持客户端与服务器之间较长时间的连接,允许服务器推送新的信息。这些日子,网络套接字协议是实现这个更有效的方式,但网络套接字是相当新的,只在现代浏览器中有效,而流传输技术能在你能想到的任何浏览器中运用。
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。TEL:177 7030 7066 E-MAIL:11247931@qq.com
Copyright © 2019-2024 51dongshi.com 版权所有
违法及侵权请联系:TEL:177 7030 7066 E-MAIL:11247931@qq.com 本站由北京市万商天勤律师事务所王兴未律师提供法律服务


